-
How databases actually store your data
As a part of my effort to learn more about computers, I have started learning about databases. For a former analyst like me SQL should have been my bread and butter, alas companies still prefer Excel. In current organization, our database system is a little different and to understand that system better, I have decided that I must be able to compare it with industry standard systems to glean their differences.
-
Performance engineering
As I try and learn more about performance engineering of computer systems, I went through the youtube video from MIT on performance engineering.
The lecture takes us through a little bit of history of the compute resources available and what the consequences the end of moore’s law had on performance. Performance is currency for software and like money, more money gives better things. To better drive this point home, they take an example of square matrix multiply for n = 4096. -
Notes on psr
There has been a lot of focus on performance at work so I am doing a deep dive on PSR testing.
-
Notes From A Course On Information Theory
Information is simply the data received about a fact that resolves uncertainty.
Information theory as a field was created by Claude Shannon’s work, A Mathematical Theory of Communication. I think his treatise is the first to look information mathematically. Shannon was interested in reducing the communication losses in transmission over phone lines. So a lot of textbooks use examples of transmission of text messages across phone lines.
Information theory is also closely related to probability.
Essentially more surpising the outcome of an event, the more information it carries.
Information is quantified in the language of the probability:
Given a discrete random variable X, with N possible values x1, x2,….,xn and their associated probabilities p1, p2,….,pn, the information received when learning that choice was xi:L(Xi) = log2(1/pi)
The question I had was why was base 2 used for the log. Surprisingly the Wikipedia page on this is quite useful and accessible to a noob :the information that can be stored in a system is proportional to the logarithm of N possible states of that system, denoted logbN
Effectively, 1 bit is the answer to a yes/no question. Yes and No have equal probabilities -
Notes on operating systems
I have got some free time on my hand and operating systems sounds like an interesting thing to read up on. I picked OPERATING SYSTEM CONCEPTS by SILBERSCHATZ, GALVIN and GAGNE because someone on Twitter recommended it.
A process is the unit of work in a modern time-sharing system. Informally, a process is a job that the computer must complete.
A process is an active entity where as a program is an passive entity. A program becomes a process when an executable file is loaded into memory.
A process usually includes: - program code - text section
- program counter - includes the current activity
- process stack - contains temporary data (such as function parameters, return addresses and local variables)
- data section - contains global variables
- heap - memeory dynamicall allocated during process runtime
####Process in memory
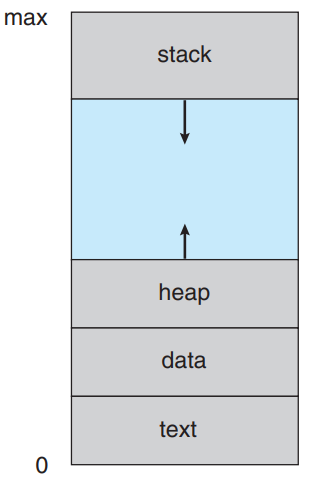
Stack is a Last In First Out (LIFO) data structure. Frequently used with function calls.
For x86 CPU's the stack starts out at high memory addresses and grows downwards (as shown by the arrow in the figure above). When a program exceeds all of the space allocated for the stack the program crashes beacuse of stackoverflow (Now I know how stackoverflow got its name).
Stacks usually allow two operations: push and pop. Push is adding items to the top of the stack and pop is removing items from the top of the stack. Inserting or removing items from the middle of the stack is not permitted.
[There's a great animation by Delroy A. Brinkerhoff](https://icarus.cs.weber.edu/~dab/cs1410/textbook/4.Pointers/memory.html)
Heap memory is dynamically allocated by the program. Here there is no restriction that memory can only be accessed at the top. Data can be inserted or removed from anywhere in the heap. -
Notes on concurrency in operating systems
I am following the CS162: Operating Systems and Systems Programming course on youtube and these are my notes.
This is the perfect way to spend your holiday morning.
Thread is a unit of execution. It has it’s own registers and stack but shares memory with other threads in the process. -
Symmetry in scheduling
As the size of the problem set increases it generally becomes harder and harder to find optimal solutions oe even feasible solutions. One way to deal with this is to introduce symmetry breaking constraints. If we look at scheduling problems, what we are essentially doing is assigning tasks to machines and esnuring that constraints are met. In constraint programming lingo the start and end time for the task would be variables and the domain of the variables would be all possible values for the variables.
-
Running google or Tools on aws
I work primarily on scheduling problems which are NP-Hard. As the size of the input increases the time to find a optimal or even a feasible solution increases. My workstation is remarkably under-powered to test out larger instances of the job shop scheduling problems. So I am going test the input data out on AWS free-tier. Hopefully I can convince my bosses that powerful workstations have a good return on investment!
-
Notes on rl in finance book
These are my notes as I read through the Foundations of reinforcement learning book by Ashwin Rao and Tikhon Jelvis.
-
Machine learning for job shop scheduling
There is an interesting paper from Tassel et. al on using reinforcement learning for the job shop scheduling problem. The JSSP is an NP-Hard problem. This blog is basically my notes on their paper.
Motivation for the paper
Reinforcement learning has been quite successful in recent times from AlphaGo to Atari. The authors are interested in trying out this technology that is quite successful in one field and apply it to a different field. They propose three advantages of using RL for scheduling:
- RL agents can offer more flexibility as compared to traditional methods
- Traditional methods like linear programming or constraint programming are deterministic and cannot model stochastic events such as machine failures, random processing times etc
- In industrial settings where the instances share a lot of similarity, lifelong learning can allow the agent to reuse what it has learnt from scheduling the past instances
- RL provides a possibility to incrementally schedule the incoming jobs as they appear in the queue by considering the impact of a schedule for known jobs on the new ones as compared to traditional methods that focus only on a given set of jobs
-
Circuit constraints in constraint programming using google or Tools
Circuit constraints are used in constraint programming to force an Hamiltonian circuit on a successor array. They are used commonly in industrial applications such as the vehicle routing problem (VRP) and the travelling salesman problem (TSP). There’s a great GIF on STEM lounge for visualizing the TSP.
-
Job shop scheduling in python
Job shop scheduling is problem where the user has to schedule multiple jobs on multiple machines. At a small scale it is easy enough to solve by hand. But when the number of jobs and available machines is relatively large, it is almost impossible to solve by hand. In computer science it is known as an NP-Complete Problem. In technical terms for every instance of the job shop scheduling problem with more than 3 available machines there no known exact algorithms that can solve it in polynomial time.
-
Markov decision processes
Markov decision process is a mathematical tool for modelling stochastic control problems. Another way to look at them is that they can be used for sequential decision making. Sidenote: There is a great lecture series on YouTube by David Silver which explains MDPs and how they are used in reinforcement learning.
A key assumption is that all the states follow the Markov property which basically states that the future is independent of the past given the present.Defining MDPs
An MDP is a 4-tuple M : M = (S ,A ,Pa ,Ra)
- S is the state space
- A is the action space
- Pa(s* ,s’)* is the probability of going from state s to s’
- Ra(s* ,s’)* is the reward for going form state s to s’
-
Dynamic programming
Dynamic programming is widely-used technique for solving optimization problems. It was developed by Richard Bellman while he was at RAND corporation. There’s a fun anecdote on where the term dynamic programming comes from. At RAND Bellman was working on mathematical research and had a boss who had a “pathological fear and hatred of the word “research””. So protect his research from bureaucratic meddling he coined the term dynamic programming. At that time programming referred to mathematical programming (like linear programming) rather than computer programming
Dynamic programming is way to go through all the possible points in a graph but in an intelligent manner. It is based on the principle of optimality. We break the problem into sub-problems, solve the sub-problems and put the sub-problems together to solve the original problem. -
Recurrent neural networks
#Recurrent Neural Networks
-
How can information theory be used in practical optimization tasks?
- The fundamental problem of communication is that of reproducing at one point either exactly or approximately a message selected at another point. - Claude Shannon
- Here information can be thought of a being transmitted across time (by taking photographs of an event to document it) or across space (from Mumbai to Delhi) The way I imagine information theory can be used in optimization is best explained using an analogy. Suppose a man treks across a particularly tricky piece of terrain. There are numerous life-threatening obstacles in our mans path but being the intrepid traveler that he is, he successfully crosses the terrain. Now with that knowledges gained from his trek, the traveler sends information across space by using a transmitter to communicate to his team mates the safest path through the terrain. Or he may send information across time by putting up placards warning of the particularly dangerous bits of the terrain. So, how does this have anything to do with optimization?
- Usually, in practical business settings where optimization is used on a a regular basis we solve the same problem frequently with data changing across instances. Let us imagine that we are responsible for the scheduling production jobs for a small firm manufacturing firm. We use a constraint programming solver to create schedules which minimize the makespan. We use the solver every week to create schedules. After creating schedules for a bout a year, we realise that the solver runs and tries to solve the same problem, albeit with different demands, every week. The solver run of today does not consult with the solver run of yesterday. The question is useful to do so?
-
Constraint programming
Constraint programming is a way to solve optimization problems like scheduling. Students usually encounter this a graph colouring problem in their discrete mathematics class.